10000 foot view...
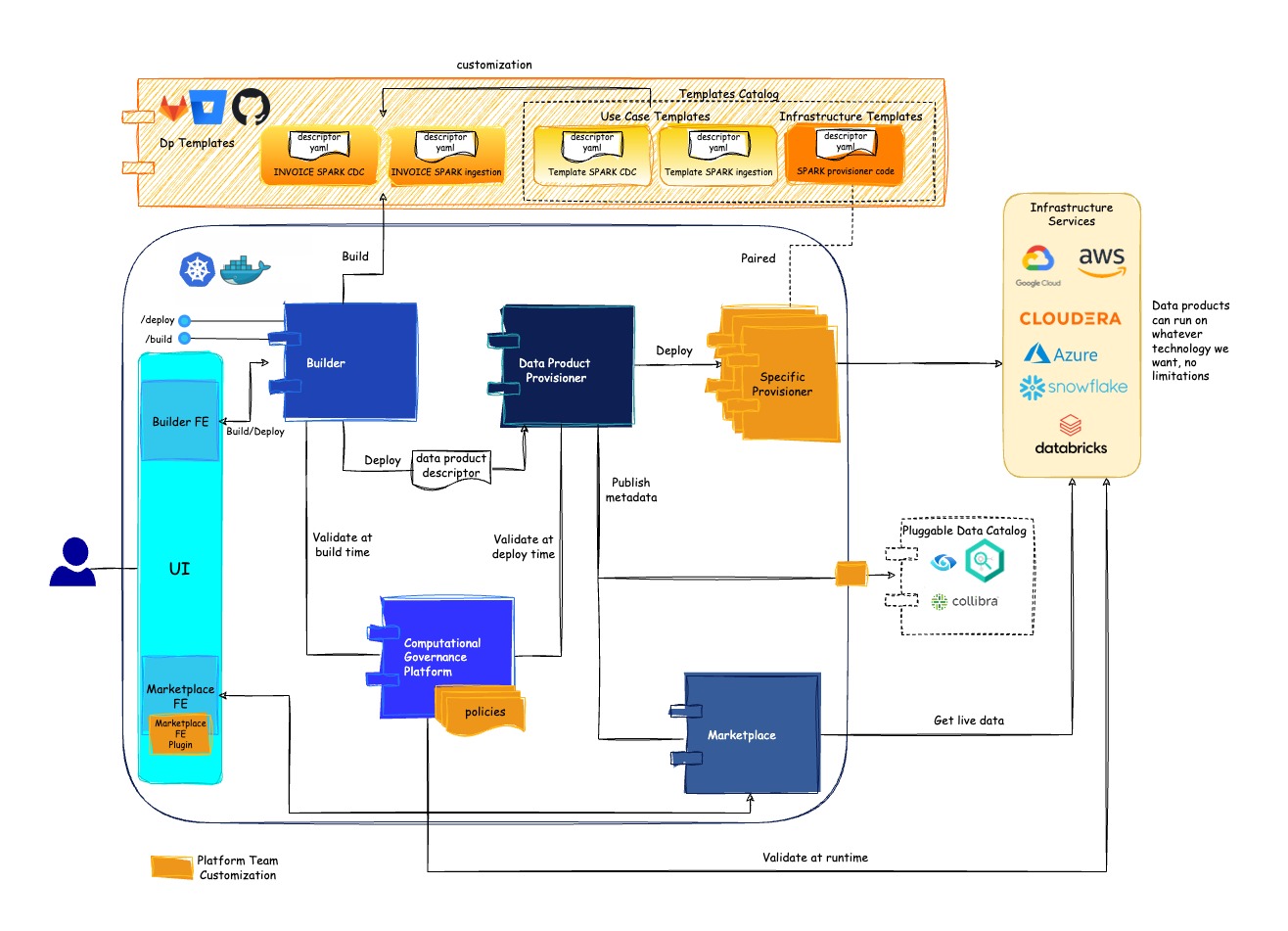
Witboost is a container-based microservices platform that counts 4 main modules:
- Builder: it implements services to create and deploy a system through the UI or the REST endpoints
- Marketplace: it implements services to access systems metadata and output access requests
- Provisioner: it handles the system provisioning on the target infrastructure
- Witboost Computational Governance: it stores Governance Policies and it validates a system descriptor against the applicable set of policies and metrics
Witboost is designed to be entirely technology agnostic, allowing users to introduce and support any technology through a template mechanism. This means that Witboost customers easily adopt changes including a new multi-cloud strategy or adding multiple technologies to an existing Data Mesh implementation. There are two kinds of templates:
- Infrastructure Template (or technology adapter)
- Use cases Template
A use case template is a specialized System Specification and the associated Infrastructure Template is the deployment descriptor. These templates are linked, so when a System team is using a template to build its use case, Witboost automatically chooses the linked Infrastructure Template that completely automates the deployment tasks. The same Infrastructure Template (Technology Adapter) can handle different Use Case Templates. The Infrastructure Template developers can create multiple Use Case Templates ready to be used.
Witboost provides a basic set of open-source templates and specific provisioners that can be customized by customers depending on their needs and context. This starter kit will keep growing as we add open-source templates for more and more technologies, and scaffolds that you can use to start developing your specific provisioners in your language of choice.
Templates Catalog is hosted on the customer-specific versioning platform (GitLab, Bitbucket, GitHub, etc.) and shall be accessible by the platform since templates are involved in the most important flows platform-wide.
Data Product Specification
The Data Product Specification constitutes the most important building block of the platform: it has been conceived to collect the full set of metadata to explain the structure, deployment, and quality metrics of a data product. Platform's microservices contracts have been defined on top of this information unit. This specification is open source and can be found in the reference reported below.
References:
Builder
The Builder is the module that implements the Developer / Owner experience: here Data Products are designed, created, tested, and finally sent for deployment to the Provisioner module.
Inside this module, a user can:
- Browse the templates. A template can be used to create new data products and their components.
- Browse his/her data products. This list contains all the data products that the user can access to edit the code on the source repository.
- Create new data products or components by using the templates (the wizard prompts the template mandatory fields that are part of the specification, while other metadata can be added subsequently).
- Test a data product. Verify if the data product is compliant with specifications and also is applying the rules of the federated governance. This functionality is just building a data product descriptor on the fly and testing it.
- Update a data product's release to create a new draft release.
- Deploy a data product: once there is a release the data product can be deployed. The data product descriptor is read from its committed files on the repository. The deployment operation is including tests, so it is recommended to always test data products before starting a deployment operation.
- Create a new data product version when breaking changes are introduced.
Every operation allowed from the UI (deploy/commit/test/ etc.) has an invocable API counterpart exposed by the Builder backend to enable customer automation.
Marketplace
The Marketplace module is the Data Product marketplace, where consumers can search and discover all the data products in your mesh, as well as access key information such as version, domain, status, and environments. The Marketplace is the module that enables data consumers to easily discover and explore the whole data mesh.
Within this module, consumers can interact directly with data product owners, through questions, eliminating the risk of data information loss, and managing accountability to provide full transparency about data products across the entire company. Inside the marketplace, a data product owner makes all the output ports available for consumption, with documentation, metadata, and the capability for consumers to easily request access to them.
Moreover, you don’t need to worry about compliance, if data products are available in the marketplace, that means they have already passed all policies checks, best practices and standards. Witboost automatically performs all compliance checks, that you have defined when publishing a data product.
Inside this module, consumers can:
- Search and discover data products available in the marketplace
- Understand what domains and data products are available in the different domains, and how they are connected
- Access data product details and consume one of the available output ports by requesting access
- Read and create reviews
- Read answers and ask questions to data product owners
- View all data products and inspect their dependencies through the Dependencies Graph
- Review KPIs, statistics and real-time data through Mesh Supervision
You can think of the marketplace as an actual e-commerce module, where each data product has its page to "sell" it to consumers; this page not only contains the data product details but also some ways for the consumer to express their satisfaction in consuming it.
The Marketplace Front End can be easily extended by implementing custom plugins to create new dashboards and add custom widgets.
Provisioner
The Provisioner is like the leader of a team of workers: he receives a job description and decomposes it into a series of smaller individual tasks; then assigns specific tasks to workers to execute, and when all are done declares the work completed.
The responsibilities of the Provisioner are:
- Build the provision/unprovision/validation/update acl plans given a specific Data Product Descriptor;
- Schedule the provision/unprovision/validation/update acl plans in order to generate a DAG of tasks that are executed in the queue;
- When a new template is created or updated, the Provisioning Coordinator stores its metadata;
- Store and use the validation policies;
- Schedule an Access request task for a target component to the related Technology Adapter;
- Schedule an HTTP call to the Marketplace Proxy when the provision, unprovision and access tasks are OK.
Deploy flow
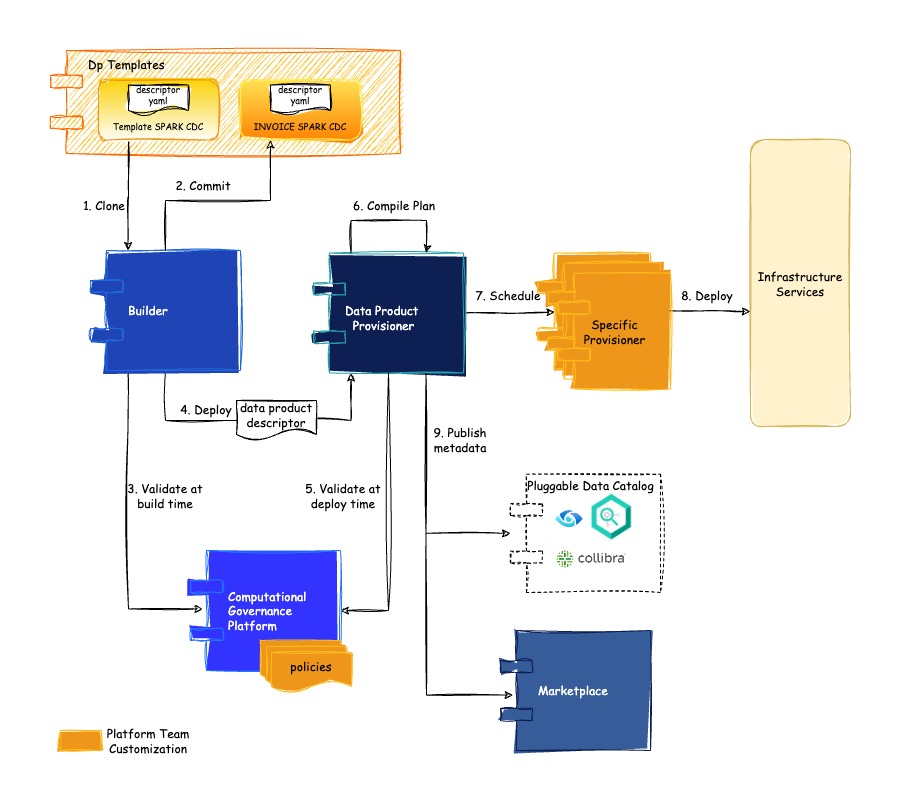
- The builder will clone Use Case Templates to create pre-built repositories for Data Products and their components
- When the Data Product and all its components are in a stable status it is possible to invoke the commit operation. When the commit operation is invoked, it will generate a data product descriptor by reading all components' repositories; after all of them have been merged, the resulting YAML Data Product Descriptor is committed along with the environment's configurations in the repository.
- While testing an existing committed snapshot, the YAML descriptor is loaded and validated against the configured policies; while the HEAD branch is tested, the descriptor is built on the spot but not published.
- The deploy operation will send one of the YAML Data Product Descriptors to the Provisioner for deployment. The deploy operation will not generate a descriptor, since it is applicable only to existing snapshot versions. For deployments, it uses instead the descriptors already committed in the repo by a previous commit invocation. The Provisioner will invoke again the validation to check that any previously committed descriptor is still valid (and also to support invocations performed outside of the Builder module).
- The Provisioner validates the descriptor by invoking the Witboost Computational Governance
- The Provisioner "compiles" the Data Product Descriptor into a Provisioning Plan
- The Provisioner schedules the Provisioning Plan calling in the right sequence the Specific Provisioners
- Each Technology Adapter executes a specific Provisioning Task for creating the specified Data Product Component
- Once the Provisioning Plan has been completed the Coordinator notifies the Marketplace and the Customer Data Catalog (if any).