Data Product Release Lifecycle
Each new data product release can be segmented in a series of steps and the Builder has been designed to effectively address this use-case. However, the flow presented here is the suggested one, every change in this flow must be carefully thought out. Typically, when improving the quality of a data product, one could experience the following steps:
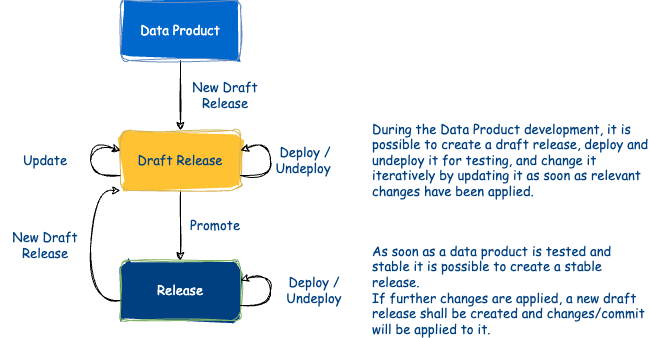
- Start of a new release cycle by creating a new draft release
- Making changes, either to metadata or to environment-specific configurations
- Saving the changes by updating the draft release
- (optional) Manually review the preview descriptor
- (optional) Check policies compliance
- Deploy the draft release and see if everything works as expected
- Promote the draft release to a stable one
Steps 4 and 5 are marked as optional since those steps are, in any case, performed automatically by the provisioning coordinator in the deployment phase. However, for step 5, errors can be reviewed also before deployment in the test section.
New Draft Release
Every new release cycle for a data product starts with a New Draft Release. A draft release is an intermediate state between the latest data product stable release and the new one. It is designed to make improvement iterations faster, without the need to increase the data product version for each single delta.
Specifically, this operation will create a new directory in the main repository under releases/ having as its name the new version number (e.g. 0.3). It will then populate this directory with all the needed descriptors:
- The complete data product descriptor
- Environment-specific configurations for each environment
Once this operation is completed, a new data product release cycle is said to be started: a new draft release is generated.
Update
The update operation is used to ensure that any changes to the draft release of a data product move only between consistent states. Use it when you want to reflect your changes to the draft release files managed by Witboost. Updating a draft release means that all changes to descriptors and configurations made in the repository will be reflected to the draft release descriptors and configurations (i.e. in the files inside the release directory). Please note: the changes are applied to the draft release only when an update is performed.
You can still have a preview descriptor of the changes you made before updating the release in the Edit and Test tab. Only when the draft release is updated the changes you made to the descriptor are actually reflected onto the release.
Modifying files inside the release directory is allowed. However, this practice is highly discouraged, since all changes there will be overwritten by any further update operation.
Deploy
Deploy will take the data product descriptor connected to a release and deploy the infrastructure to the selected environment. Before that, it will ensure that the descriptor is well-formatted and compliant with the defined policies for the given environment (you can test its validity against the data governance's policies, refer to Data Product Validation section). If all checks are passed and the deployment is successful, the data product is published into the marketplace, so that consumers can start using it.
Remember to update your draft release before deploying: only in this way you will ensure that the data product descriptor with the latest changes is being sent to the provisioning coordinator.
The Data Product deployment will start the underlying deployment of all of its components, in a sequence defined by the "dependsOn" relations among them (check the deployment section and/or the provisioning section for more details). After the deploy operation is invoked, it can happen that:
- the deployment fails with a validation error: in this case, the deployment did not start at all. The environment is not touched, and you can simply click on the "bug" icon to see what validation error caused the failure. Then after solving the error, you can just try to deploy everything again.
- one of the deployment steps fails. In this case, the Data Product is in a corrupted state, since some of its components may be already deployed and available, while others are not. In this case, Witboost does not automatically roll back any of the already deployed components, since their deployment could require a long time or a significant amount of resources. From here the user can decide to solve the deployment problems and trigger another deployment operation, or to undeploy the whole data product (this will remove the components already deployed).
- the deployment completes with success. One of the steps that the Provisioner module performs is the registration of the deployed data product in the Marketplace. So from now on the data product can be visible to all the consumers that access the Marketplace.
Remember that the Marketplace is updated only by deploy operations, so you will need to perform another deploy operation in case you want to change the metadata visualized in the Marketplace.
Since all the Technology Adapters must be idempotent, deploy operations are idempotent as well, so you can always re-deploy an already deployed data product to update its metadata.
When changes are required to improve the data product or to fix some problems, the components' repositories (or the data product repository itself) can be edited accordingly, and a new data product release can be generated and deployed. Remember that only one deployment per data product and environment should be active at the same time, so if you are making some structural changes, you could decide to undeploy the current data product before deploying it again.
To delete a component, you can simply remove it from Witboost as described in the previous section. Remember that this will not affect any deployed instance of the data product, so to make this deletion effective you should undeploy the current version and deploy it again. Similarly, when you want to completely delete a data product, you should first undeploy it, and then start removing each component entity, and then the data product entity itself.
When you are going to introduce changes that will break retro-compatibility on the contract that the data product exposes to its consumers (e.g. the output ports it exposes) a new version of the data product must be created. You can do that by accessing the three dots menu of the data product and selecting New version. This will create a completely new data product and components with a different major version. Those can be considered as completely new components belonging to a brand-new data product.
Promoting a release
Promoting a release means to change a data product draft release to a concrete one, by assigning a final version structure. From now on the release is immutable, and new changes must be performed by creating a new draft release.
After the release promotion, the release cycle is closed and the old releases are frozen. To make further changes a new draft release is needed.